

Zur Ordnungswirkung fundamentaler Ideen der Informatik am Beispiel der theoretischen Schulinformatik
Beispiel 3: LOGO für Arme
Eckart Modrow
Max-Planck-Gymnasium
Theaterplatz 10
37073 Göttingen
emodrow@astro.physik.uni-goettingen.de
Bem.: das Beispiel stammt in dieser Version aus der Virtuellen Lehrerweiterbildung Informatik in Niedersachsen: www.vlin.de
Das folgende Beispiel soll anhand eines Standardthemas der Schulinformatik - dem Parsen von Sprachkonstrukten - zeigen, wie mithilfe der erlernten Methoden auf einfachem Niveau ein "Computersprache" gebastelt werden kann, die zwar nicht sehr umfangreich ist, aber sehr zum Spielen einlädt und damit zum Spaß am Unterricht beiträgt. Geplant wird eine Unterrichtseinheit für einen Oberstufenkurs, der mit Java vertraut ist - in diesem Fall mit dem JBuilder von Borland. Weiterhin sollten Grundkenntnisse aus dem Bereich der endlichen Automaten vorhanden und Syntaxdiagramme vertraut sein. Es zahlt sich also aus, wenn im Sinne des vorbereitenden Lernens diese Konstrukte schon vorher mehrmals benutzt worden sind, und es kann auch nichts schaden, wenn schon einmal eine Turtlegrafik implementiert wurde. Der vorhergehende Unterricht hat ähnlich wie in den Naturwissenschaften u. a. die Aufgabe, Erfahrungen zu ordnen und ggf. zu verschaffen, anhand derer eine informatische Begriffsbildung erfolgen kann, die weitgehend der Vermittlung fundamentaler Ideen entspricht. Die entwickelten Begriffe sind in einem geeigneten Kontext einzuführen und anzuwenden, sodass im weiterführenden Unterricht auf sie aufgebaut werden kann. Unter dieser Voraussetzung stehen dann z. B. in der Sekundarstufe II genügend Erfahrungen und Unterrichtszeit zur Verfügung, um z. B. theoretische Inhalte angemessen vertieft zu unterrichten. Wenn es also möglich ist, dann sollten schon sehr früh Begriffe wie Zustand, Zustandswechsel, Automat, ... benutzt werden - auch wenn es nicht unbedingt nötig ist. Solange es nicht stört, kann damit weiterführender Unterricht effizient vorbereitet werden.
Die - meist vereinfachten - Konstrukte gängiger Programmiersprachen können geeignetes Übungsmaterial liefern, um das Parsen als Anwendung endlicher Automaten zu verstehen und zu üben. Man kann mit ihnen alleine allerdings nicht so recht etwas anfangen. Gesucht sind deshalb Beispiele ähnlicher Komplexität (oder Einfachheit - je nachdem wie man es sieht), die in sich sinnvolle Anwendungen bilden. Als ein solches Beispiel hat die einfache Grafiksprache LOGO für Arme sehr bewährt. Beachten wir, dass es m. E. Aufgabe des Informatikunterrichts ist, den Schülerinnen und Schülern zu einem gültigen Computermodell zu verhelfen, dann bietet ein solches kleines Projekt die Möglichkeit, über konstruktive Arbeit die Arbeitsweise eines Compilers bzw. Interpreters zu erfahren.
Sehen wir uns zuerst ein mögliches Ergebnis an:
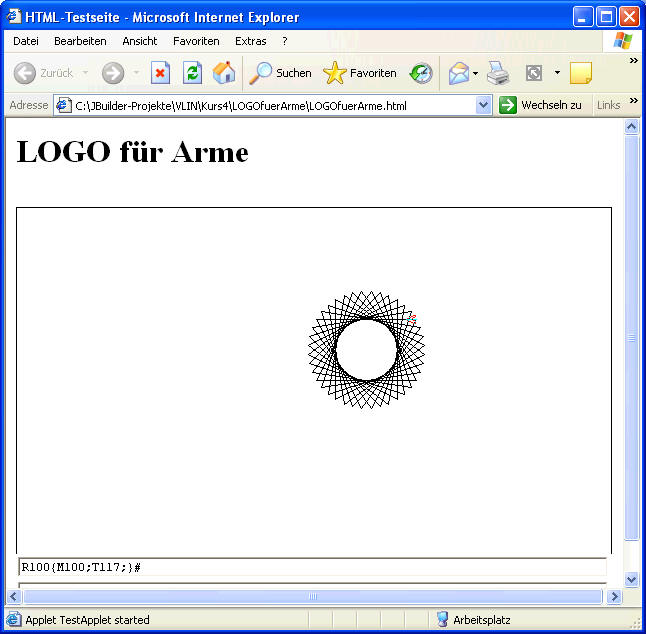
In das obere Textfeld am unteren Rand des Applets werden Befehle eingegeben, die von der Turtle, dem kleinen Pfeil in der Bildmitte, ggf. ausgeführt werden. Im unteren Textfeld sollen Fehlermeldungen etc. erscheinen. Geben wir einen gültigen Turtlebefehl ein (was immer das sein mag), dann wird der ausgeführt. Enthält die Zeile Fehler, dann werden sie angezeigt.
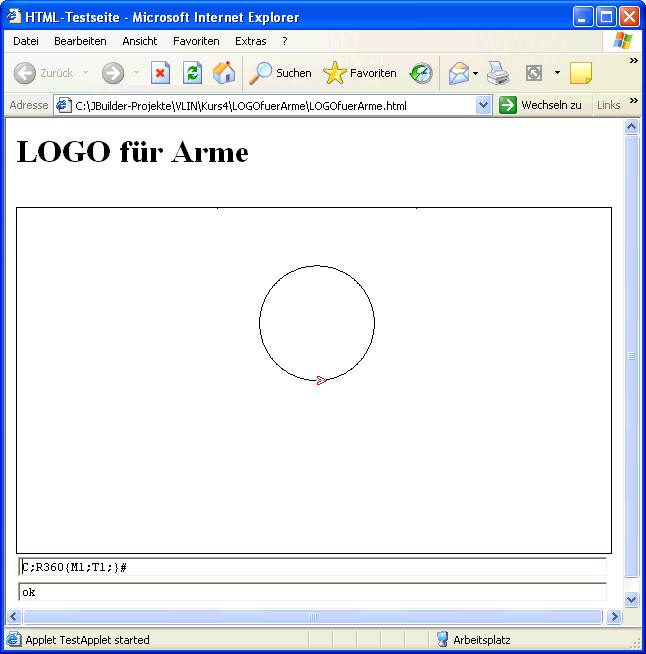
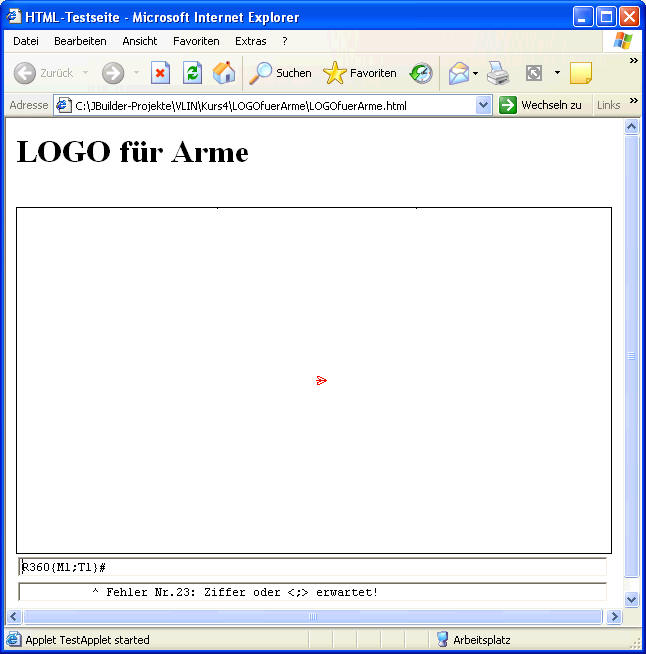
Dafür benötigen wir natürlich eine eine Turtlegrafik!
Die Syntax der Sprache
Würden wir es akzeptieren, dass vollständige Turtlebefehle unsere Sprache bilden, dann bekämen wir einen sehr umfangreichen Parser, der beispielsweise zur Erkennung des Befehls penDown() neun Zustände "verbraten" müsste. Wir reduzieren deshalb die Befehle auf einzelne Zeichen. Dabei verschenken wir nichts von den Möglichkeiten, erwerben aber einfachere Konstrukte.
Die Sprachdefinition über Syntaxdiagramme erfordert einiges an Überlegungen, denn besonders bei arbeitsteiligem Unterricht in Projektphasen müssen die gemeinsamen Grundlagen der Gruppen völlig klar sein. Es ist deshalb sinnvoll, diesen Schritt gemeinsam durchzuführen, weil nicht nur die Ergebnisse, sondern noch viel mehr die Begründungen für eine spezielle Wahl wichtig für die weitere Arbeit sind. Man sollte also zusammen gründlich diskutieren und auch Alternativen in Betracht ziehen, bevor man sich für eine Lösung entscheidet.
In diesem Fall wollen wir die folgende Version wählen:
LOGO für Arme:
| Programmkonstrukt | Syntaxdiagramm | Erläuterung |
|
Programm
|
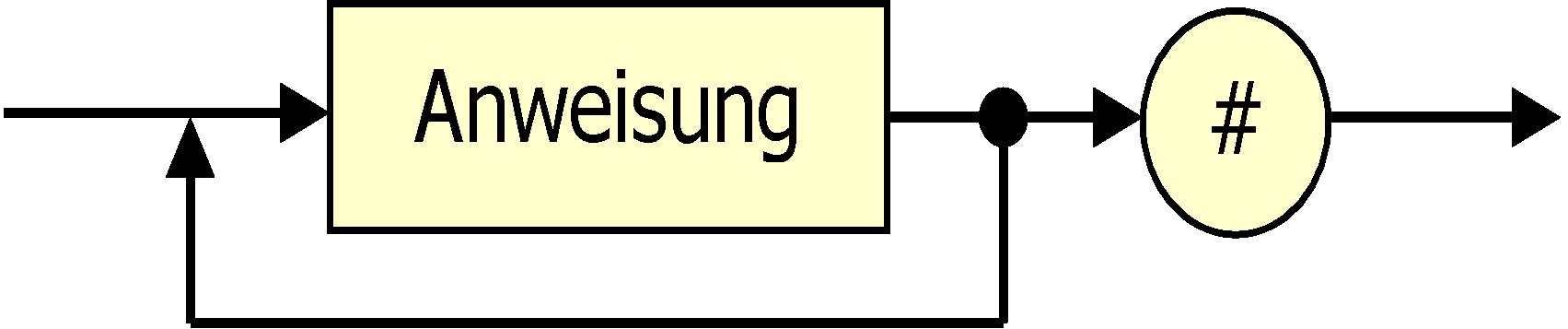 |
Ein definiertes Ende-Zeichen (hier: <#>) erleichtert meist die Analyse einer Zeichenfolge. Davon machen viele Sprachen Gebrauch: <end.> bei Delphi, <;> nach jedem Java-Befehl
|
| Anweisung | 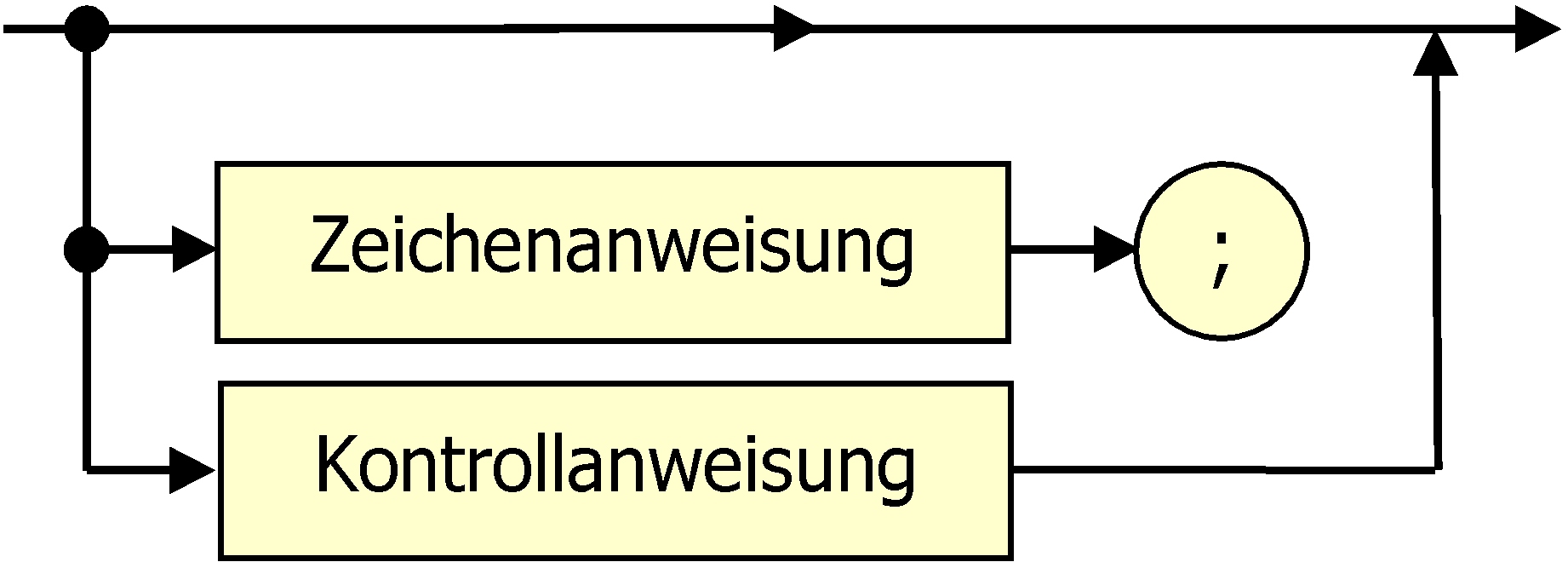 |
Damit die Sprache mit endlichen Automaten analysierbar bleibt, müssen wir geschachtelte Strukturen vermeiden. (Dieser Punkt muss bei der Diskussion der Sprache deutlich herausgearbeitet werden!) In unserem Fall erreichen wir das, indem wir zwei unterschiedliche Arten von Befehlen benutzen. Diese Trennung ergibt sich auch aus der Sache, weil die Zeichenbefehle die Turtle kontrollieren, während die Kontrollbefehle den Programmablauf steuern. |
| Kontrollbefehl | 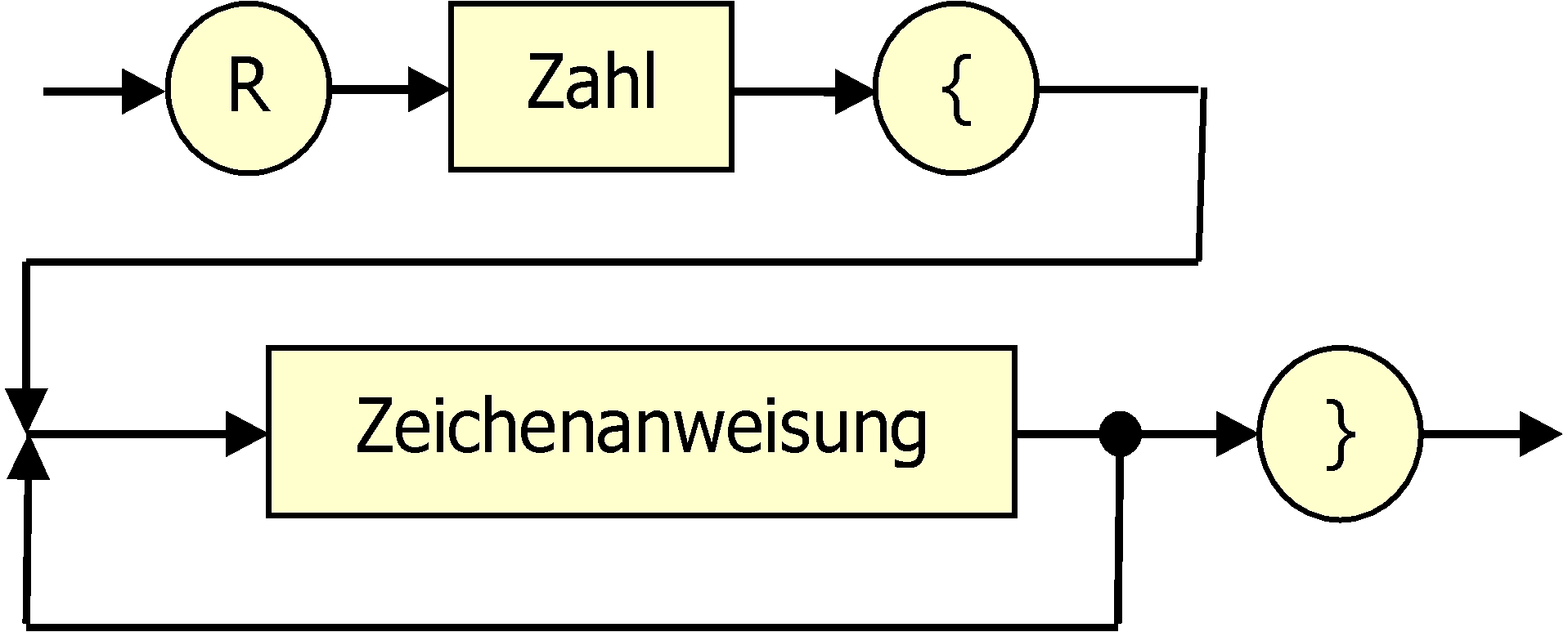 |
Die Syntax ist etwas an Java angelehnt (mit den geschweiften Klammern). Es können nur Zeichenanweisungen mehrfach wiederholt werden. |
| Zeichenanweisung | 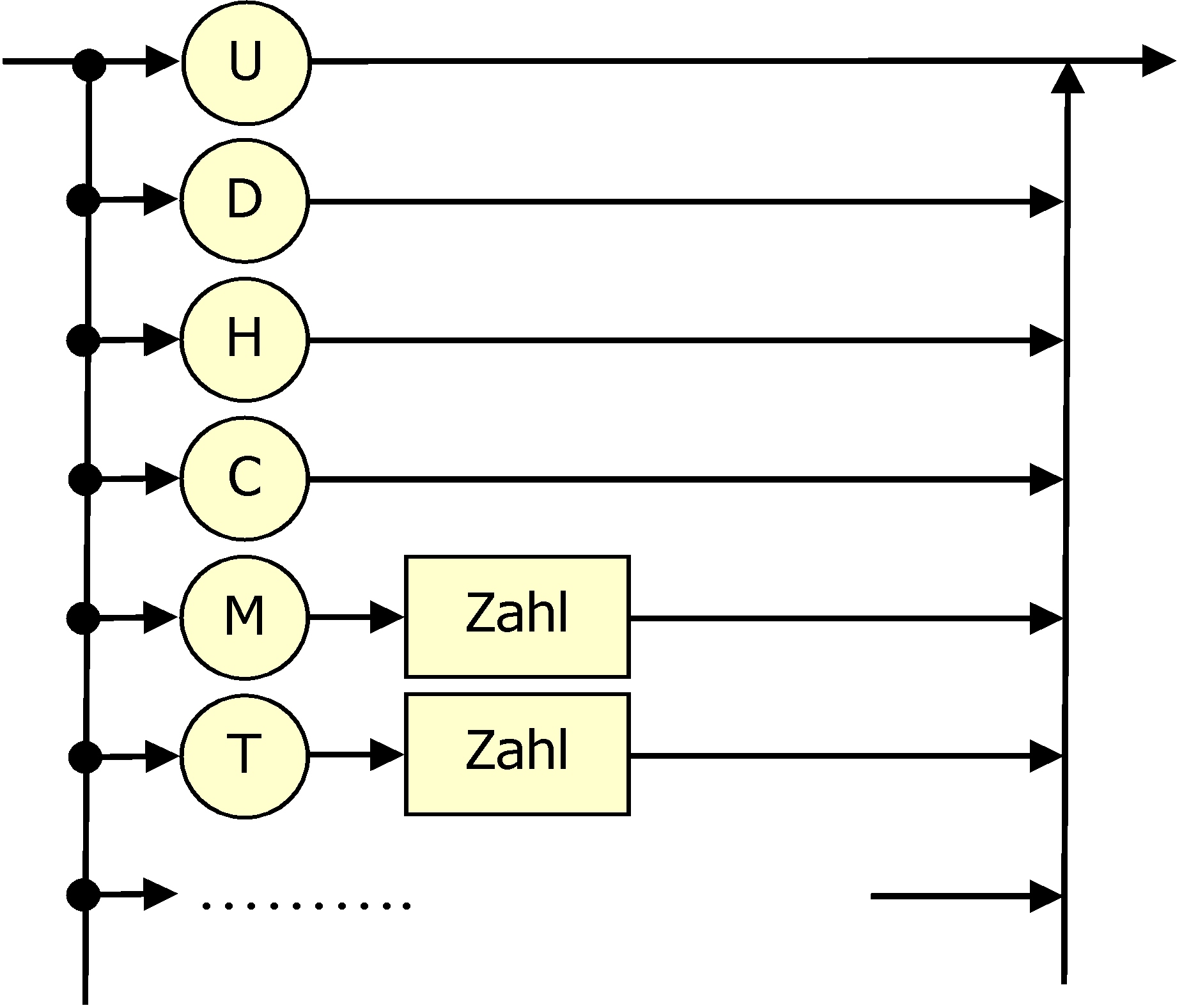 |
penUp
penDown
Home
Clear
Move ...
Turn ...
... weitere Befehle möglich
|
Mögliche Befehlsfolgen sind
- ein Quadrat: M100;T90;M100;T90;M100;T90;M100;T90;#
- ebenso: R4{M100;T90}#
- ein Dreieck: M100;T90;M100;H;#
- ein Kreis: R360{M1;T1;}#
Der Turtleparser
Die Analyse der Sprache erfolgt durch einen erkennenden Automaten, der - in diesem Fall - den Endzustand Nr. 99 hat. Fehlerzustände haben Nummern ab 20. Die Kanten zu diesen sind nicht eingezeichnet worden. Das Eingabealphabet besteht aus den zulässigen Zeichen:E = {U,D,H,C,M,T,R,0,1,2,3,4,5,6,7,8,9,{,},;,#}
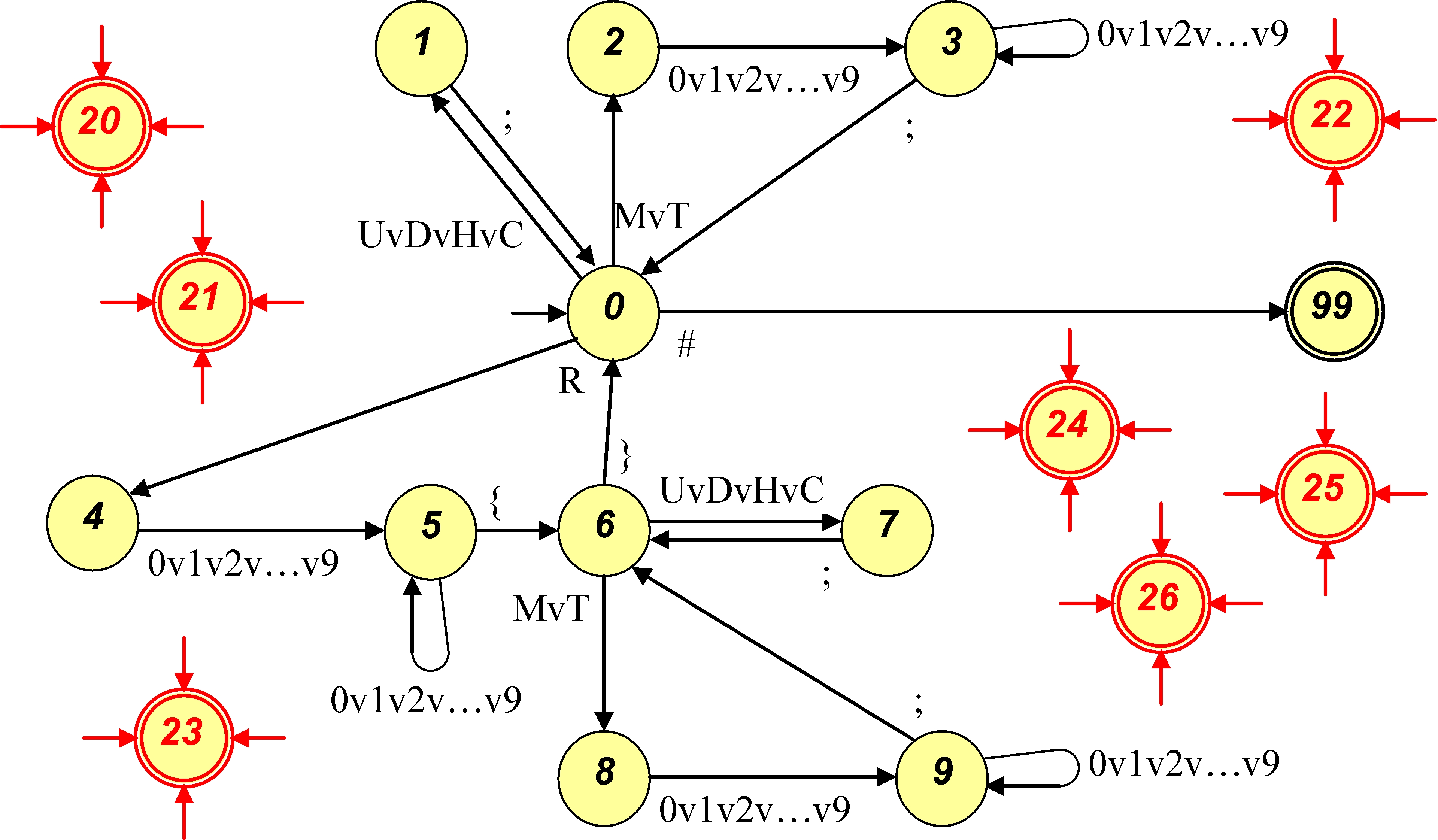
Der Parser wird als eigene Java-Klasse realisiert.
Der Parser muss vom Applet auch benutzt werden. Dazu wird erstmal eine Instanz des Parsers erzeugt.
Turtleparser tp = new Turtleparser();
Danach wird der zu überprüfende String s dem Parser zeichenweise übergeben. Zwischendurch wird nachgesehen, ob ein Fehlerzustand erreicht wurde. Falls das der Fall ist, wird eine entsprechende Fehlermeldung erzeugt. Zuletzt wird überprüft, ob der Endzustand erreicht wurde. In Abhängigkeit davon wird das Ergebnis des Parsings zurückgegeben.
private boolean parse(String s)
Der Turtleinterpreter
Der Scanner
Das Applet
private void werteAus(String s)
LOGO für Arme
Die Java-Klassen in Form eines zip-Files können hier heruntergeladen werden.
Kommentare